파이썬을 꽤나 오래 사용햇지만, 파이썬이 VM 위에서 돌아가는 언어라는걸 올해 초 알게 되었습니다. 회사, 우선순위 높은 공부 등의 이유로 미루어 왔던 내용을 정리해서 올려봅니다.
해당 글은 500 Lines or Less | A Python Interpreter Written in Python을 번역한 글입니다.
Interperter란
interpreter라는 단어는 Python을 논의 할 때 다양한 방식으로 사용될 수 있습니다.- terminal에
python을 입력하면 나오는 인터프리터는Python REPL을 참조합니다.
“파이썬 인터프리터”를 “파이썬”과 사용하여 처음부터 끝까지 파이썬 코드를 실행하는 것으로 대부분 알고 있습니다.
이 장에서 interpreter는 좁은 의미를 가지고 있으며, 파이썬 프로그램을 실행하는 마지막 단계입니다.
Python 코드가 인터프리터에서 실행되기 전 과정
- 렉싱(어휘 분석)
- 파싱
- 컴파일
해당 과정을 거치면 프로그래머의 소스 코드에서 인터프리터가 이해할 수 있는 명령이 포함된 구조화된 코드 개체로 변환합니다. 인터프리터의 임무는 이러한 코드 객체를 가져와 처리하는 것 입니다.
Python을 포함한 대부분의 interpreter 언어에는 컴파일 단계가 포함됩니다.
Python은 C 또는 Rust와 같은 “컴파일 된” 언어와 달리 Ruby 또는 Perl과 같은 “해석 된”언어라고도 합니다.
파이썬을 “해석”이라고 부르는 이유 : 컴파일 단계가 컴파일 언어(C 언어 등)보다 적은 작업을 수행합니다. (인터프리터가 상대적으로 더 많은 작업을 수행)
또한, 이 장의 뒷 부분에서 볼 수 있듯이 Python 컴파일러는 C 컴파일러보다 프로그램 동작에 대한 정보가 훨씬 적습니다.
Python Interpreter
- Python 인터프리터는 가상 머신입니다.
- 실제 컴퓨터를 에뮬레이트하는 소프트웨어입니다.
가상 머신은 스택 머신입니다. 특정 메모리 위치에 쓰고 읽는 레지스터 머신과는 달리 여러 스택을 조작하여 작업을 수행합니다.
파이썬 인터프리터는 바이트 코드를 읽어 실행합니다. 입력은 바이트 코드이며 명령어 세트 입니다.
Python을 작성할 때 렉서, 파서 및 컴파일러는 인터프리터가 작동 할 코드 객체를 생성합니다.
각 코드 객체에는 실행할 명령어 세트 (바이트 코드)와 인터프리터에 필요한 기타 정보가 포함되어 있습니다.
바이트 코드는 Python 코드의 중간 표현입니다. 인터프리터가 이해할 수있는 방식으로 작성한 소스 코드를 표현합니다.
어셈블리 언어가 C 코드와 하드웨어 간의 중간 역할을 하는 방식과 유사합니다.
Small Interpreter
이를 구체적 이해하기 위해 숫자만 덧셈 할 수 있는 인터프리터로 시작하겠습니다. (세 가지 명령만 동작)
실행할 수 있는 모든 코드는 서로 다른 이 세 가지 명령어 조합으로 구성됩니다.
세 가지 명령은 다음과 같습니다.
- LOAD_VALUE
- ADD_TWO_VALUES
- PRINT_ANSWER
이 장에서는 어휘 분석기, 파서는 컴파일러에서 명령어 세트가 생성되는 것과는 관련이 없기 때문에 다루지 않습니다.
7 + 5인 경우
다음과 같은 명령어 세트를 생성합니다.
1
2
3
4
5
6
what_to_execute = {
"instructions": [("LOAD_VALUE", 0), # the first number
("LOAD_VALUE", 1), # the second number
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5] }
Python 인터프리터는 스택 머신이므로 스택을 조작하여 두 개의 숫자를 덧셈합니다.
- 첫 번째 명령어(
LOAD_VALUE)를 실행하고 첫 번째 숫자를 스택에 푸시하는 것으로 시작합니다. - 두 번째 숫자도 스택에 푸쉬합니다.
- 세 번째 명령어인
ADD_TWO_VALUES에서는 두 숫자를 꺼내서 더한 다음 결과를 스택에 푸시합니다. - 마지막으로 스택에서 답변을 꺼내 출략합니다.
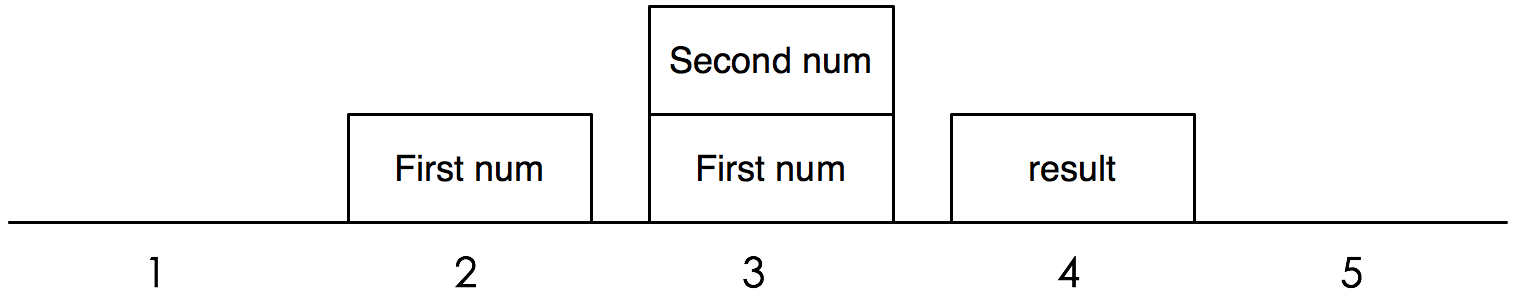
이 LOAD_VALUE 명령어는 인터프리터에게 숫자를 스택에 푸시하라고 지시하지만 명령어만으로는 숫자를 지정하지 않습니다. 각 명령어에는 로드 할 번호를 찾을 위치를 인터프리터에게 알려주는 추가 정보가 필요합니다. 따라서 우리의 명령어 세트는 명령어 자체와 명령어에 필요한 상수 목록의 두 부분으로 구성됩니다. (Python에서 “instructions”라고 부르는 것은 바이트 코드이고 아래의 “what to execute”객체는 code 객체 입니다.)
명령어에 값 대신 인덱스를 사용하는 이유?
- 숫자 대신 문자열을 더하는 경우, 문자열은 동적이기 때문에 명령어에 문자열을 쓰는 것을 선호하지 않습니다.
- 값을 쓰게 되면 어느 복사가 일어남. 이 디자인은 필요한 각 개체의 복사본을 하나만 가질 수 있음.
ADD_TWO_VALUES에서 다른 명령어가 필요한지 궁금 할 것 입니다. 사실, 두 개의 숫자를 더하는 간단한 경우에 대한 예제는 너무 간단합니다. 그러나 이 명령어는 더 복잡한 프로그램을 위한 기초입니다. 예를 들어 지금까지 정의한 명령어만으로 올바른 명령어 집합이 제공되면 이미 세 개의 값 또는 임의의 값을 더할 수 있습니다. 스택은 인터프리터의 상태를 추적 할 수 있는 깨끗한 방법을 제공하며 더 많은 복잡한 경우를 지원할 수 있습니다.
이제 인터프리터를 작성해 봅시다. 인터프리터 객체에는 스택이 있으며 list으로 표시됩니다. 객체에는 각 명령을 실행하는 방법을 설명하는 메서드도 있습니다. 예를 들어,LOAD_VALUE의 경우 인터프리터는 값을 스택에 푸시합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Interpreter:
def __init__(self):
self.stack = []
def LOAD_VALUE(self, number):
self.stack.append(number)
def PRINT_ANSWER(self):
answer = self.stack.pop()
print(answer)
def ADD_TWO_VALUES(self):
first_num = self.stack.pop()
second_num = self.stack.pop()
total = first_num + second_num
self.stack.append(total)
이 세 가지 함수는 인터프리터가 이해하는 세 가지 명령을 구현합니다. 인터프리터는 모든 것을 하나로 묶고 실제로 실행하는 함수가 하나 더 필요합니다. 바로 run_code입니다.
메서드 run_code는 what_to_execute 위에서 정의한 dict을 인수로 사용합니다. 각 명령어를 반복하고 해당 명령어에 대한 인수가 있는 경우 처리한 다음 인터프리터 객체에서 해당 메서드를 호출합니다.
1
2
3
4
5
6
7
8
9
10
11
12
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
numbers = what_to_execute["numbers"]
for each_step in instructions:
instruction, argument = each_step
if instruction == "LOAD_VALUE":
number = numbers[argument]
self.LOAD_VALUE(number)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
이를 테스트하기 위해 객체의 인스턴스를 생성한 다음 run_code 위에 정의 된 7 + 5를 추가하기위한 명령어 세트로 메서드를 호출할 수 있습니다.
1
2
interpreter = Interpreter()
interpreter.run_code(what_to_execute)
물론 답은 12입니다.
이 인터프리터는 매우 제한적이지만이 프로세스는 실제 Python 인터프리터가 숫자를 추가하는 방식과 거의 동일합니다. 이 작은 예제에서도 몇 가지 유의해야 할 사항이 있습니다.
- 일부 명령에는 인수가 필요합니다. 실제 Python 바이트 코드에서는 약 절반 정도의 명령어에 인수가 있습니다.
- 인수는 예제에서와 같이 명령어로 포장됩니다. 명령어에 대한 인수는 호출되는 메서드에 대한 인수와 다릅니다.
ADD_TWO_VALUES에는 인수가 필요하지 않습니다. 대신 함께 더할 값이 인터프리터 스택에서 튀어 나왔습니다. 이것은 스택 기반 인터프리터의 정의 기능입니다.
이것은 스택 기반 인터프리터의 정의 기능입니다.를 유추하자면 인터프린터의 구현에 따라 실제 구현이 달라질 수 있는 것 같습니다.
인터프리터를 변경하지 않고 유효한 명령어 세트가 주어지면 한 번에 두 개 이상의 숫자를 추가 할 수 있습니다.
아래 명령어 세트를 고려하십시오. 어떤 일이 일어날 것으로 예상합니까? 컴파일러가 있다면이 명령어 세트를 생성하기 위해 어떤 코드를 작성할 수 있습니까?
1
2
3
4
5
6
7
8
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("LOAD_VALUE", 1),
("ADD_TWO_VALUES", None),
("LOAD_VALUE", 2),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5, 8] }
이 시점에서 우리는이 구조가 어떻게 확장 가능한지 볼 수 있습니다. 우리는 연산을 위해 인터프리터 객체에 메소드를 추가 할 수 있습니다(컴파일러가 잘 명령어 세트를 만들어 준다는 가정하에).
변수
다음으로 인터프리터에 변수를 추가해 보겠습니다. 변수에는 변수 값을 저장하기위한 명령어 STORE_NAME가 필요합니다 .
변수 이름에서 값으로의 매핑을 검색하기 위한 명령어는 LOAD_NAME입니다.. 지금은 네임 스페이스와 범위를 무시하므로 인터프리터 객체 자체에 변수 매핑을 저장할 수 있습니다.
마지막으로 what_to_execute 상수 목록과 함께 변수 이름 목록이 있는지 확인해야합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> def s():
... a = 1
... b = 2
... print(a + b)
# a friendly compiler transforms `s` into:
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("STORE_NAME", 0),
("LOAD_VALUE", 1),
("STORE_NAME", 1),
("LOAD_NAME", 0),
("LOAD_NAME", 1),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [1, 2],
"names": ["a", "b"] }
새로운 구현은 아래와 같습니다. 어떤 이름이 어떤 값에 바인딩되어 있는지 추적하기 위해 __init__메서드에 dict을 추가합니다.
우리는 또한 STORE_NAME 및 LOAD_NAME 추가 할 것입니다. 이러한 메서드는 먼저 해당 변수 이름을 조회 한 다음 dict을 사용하여 해당 값을 저장하거나 검색합니다.
명령어에 대한 인수는 이제 두 가지 다른 의미를 가질 수 있습니다. “숫자(값)” 목록에 대한 인덱스거나 “이름” 목록에 대한 인덱스 일 수 있습니다.
인터프리터는 실행중인 명령어를 확인하여 어떤 것(숫자 인덱스, 변수 매핑 인덱스)이되어야하는지 알고 있습니다. 우리는 인수가 의미하는 바에 대한 명령어 매핑을 별도의 메서드로 나눌 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class Interpreter:
def __init__(self):
self.stack = []
self.environment = {}
def STORE_NAME(self, name):
val = self.stack.pop()
self.environment[name] = val
def LOAD_NAME(self, name):
val = self.environment[name]
self.stack.append(val)
def parse_argument(self, instruction, argument, what_to_execute):
""" Understand what the argument to each instruction means."""
numbers = ["LOAD_VALUE"]
names = ["LOAD_NAME", "STORE_NAME"]
if instruction in numbers:
argument = what_to_execute["numbers"][argument]
elif instruction in names:
argument = what_to_execute["names"][argument]
return argument
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
if instruction == "LOAD_VALUE":
self.LOAD_VALUE(argument)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
elif instruction == "STORE_NAME":
self.STORE_NAME(argument)
elif instruction == "LOAD_NAME":
self.LOAD_NAME(argument)
5 개의 명령만으로도 run_code 동작이 복잡해지기 시작했습니다. 이 구조를 유지한다면 각 명령어어가 추가될수록 if문 분기가 계속해서 추가될 것입니다.
여기에서 Python의 동적 메서드 조회를 사용할 수 있습니다. 우리는 항상라는 FOO명령을 실행하기 위해 호출되는 메서드를 정의 할 FOO것이므로 Python의 함수 getattr를 사용하여 즉시 메서드를 조회 할 수 있습니다.
그러면 run_code 방법은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
def execute(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
bytecode_method = getattr(self, instruction)
if argument is None:
bytecode_method()
else:
bytecode_method(argument)
실제 파이썬 바이트 코드
이 시점에서 장난감 명령어 세트를 버리고 실제 Python 바이트 코드로 전환합니다. 바이트 코드의 구조는 각 명령어를 식별하기 위해 긴 이름 대신 1 바이트를 사용한다는 점을 제외하면 위에서 구현한 인터프리터의 자세한 명령어 세트와 유사합니다.
구조를 이해하기 위해 짧은 함수의 바이트 코드를 살펴 보겠습니다.
1
2
3
4
5
6
7
>>> def cond():
... x = 3
... if x < 5:
... return 'yes'
... else:
... return 'no'
...
Python은 런타임에 내부 적재(구현?)를 노출하며 REPL에서 바로 액세스 할 수 있습니다.
함수 객체 cond의 cond.__code__는 cond의 코드 객체입니다. cond.__code__.co_code는 바이트 코드입니다.
Python 코드를 작성할 때 이러한 속성을 직접 사용하는 경우는 거의 없지만 이해하기 위해 내부를 살펴볼 수 필요가 있습니다.
1
2
3
4
5
6
7
8
>>> cond.__code__
<code object cond at 0x10f6814b0, file "/Users/gim-uichan/study/python/interpreter/cond.py", line 1>
>>> cond.__code__.co_code # the bytecode as raw bytes
b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x00
\x00S'
>>> list(cond.__code__.co_code) # the bytecode as numbers
[100, 1, 0, 125, 0, 0, 124, 0, 0, 100, 2, 0, 107, 0, 0, 114, 22, 0, 100, 3, 0, 83,
100, 4, 0, 83, 100, 0, 0, 83]
바이트 코드를 출력해보면 사람이 이해하기 힘듭니다. 우리가 알 수 있는 것은 일련의 바이트라는 것뿐입니다.
다행히도 이를 이해하는 데 사용할 수 있는 Python 표준 라이브러리의 dis라는 모듈이 있습니다.
dis는 바이트 코드 디스어셈블러입니다.
디스어셈블러는 어셈블리 코드 또는 바이트 코드와 같은 기계용으로 작성된 저수준 코드를 가져와 사람이 읽을 수 있는 방식으로 출력합니다.
dis.dis를 실행하면 전달된 바이트 코드에 대한 설명이 출력됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
2 STORE_FAST 0 (x)
3 4 LOAD_FAST 0 (x)
6 LOAD_CONST 2 (5)
8 COMPARE_OP 0 (<)
10 POP_JUMP_IF_FALSE 16
4 12 LOAD_CONST 3 ('yes')
14 RETURN_VALUE
5 >> 16 LOAD_CONST 4 ('no')
18 RETURN_VALUE
출력에 대한 의미
- 첫 번째 명령어
LOAD_CONST에서 첫 번째 열 (2)의 숫자는 Python 소스 코드의 줄 번호를 나타냅니다. - 두 번째 열은 바이트 코드에 대한 인덱스로,
LOAD_CONST명령어가 위치 0 에 있음을 알려줍니다. - 세 번째 열은 사람이 읽을 수있는 이름에 매핑 된 명령어 자체입니다.
- 네 번째 열이 있으면 해당 명령어에 대한 인수입니다.
- 다섯 번째 열이있는 경우 인수가 의미하는 바에 대한 힌트입니다.
[100, 1, 0, 125, 0, 0] 이 6 바이트는 인수가 있는 두 개의 명령어를 나타냅니다.
dis.opname을 통해 100과 125가 매핑되는 명령어를 알아낼 수 있습니다.
1
2
3
4
>>> dis.opname[100]
'LOAD_CONST'
>>> dis.opname[125]
'STORE_FAST'
두 번째 및 세 번째 바이트 (1, 0)는 LOAD_CONST에 대한 인수입니다.
다섯 번째 및 여섯 번째 바이트 (0, 0)는 STORE_FAST에 대한 인수입니다.
small interpreter 예제와 마찬가지로 LOAD_CONST 는 로드 할 상수를 찾을 위치를 알아야하고 STORE_FAST는 저장할 이름을 찾아야합니다.
(Python LOAD_CONST은 장난감 인터프리터 LOAD_VALUE와 동일하며 LOAD_FAST은 LOAD_NAME과 동일합니다.) 따라서 이 6 바이트는 코드의 첫 줄 x = 3을 나타냅니다.
인수가 2 바이트인 이유
- Python이 상수와 이름을 찾기 위해 2개 대신 1byte 만 사용했다면 단일 코드 객체와 연관된 256개의
변수명/상수만 가질 수 있습니다. - 2 바이트를 사용하면 최대 256 제곱(65,536)을 가질 수 있습니다.
Python3 환경에서는 4 바이트입니다.
Python 3.6이후 각 명령어는 2byte를 사용하도록 바뀌었습니다. Changed in version 3.6: Use 2 bytes for each instruction. Previously the number of bytes varied by instruction.print(list(cond.__code__.co_code))[100, 1, 125, 0, 124, 0, 100, 2, 107, 0, 114, 16, 100, 3, 83, 0, 100, 4, 83, 0]
조건부 및 루프
지금까지 인터프리터는 명령을 하나씩 단계별로 실행하여 코드를 실행했습니다.
프로그래밍을 하다 보면 특정 명령을 여러 번 실행하거나 특정 조건에서 건너 뛰기야 하는 경우가 있습니다.
코드에서 루프와 if 문을 작성할 수 있으려면 인터프리터가 명령어 세트를 이동할 수 있어야합니다. 어떤 의미에서 파이썬은 바이트 코드의 GOTO문으로 루프와 조건을 처리합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
2 STORE_FAST 0 (x)
3 4 LOAD_FAST 0 (x)
6 LOAD_CONST 2 (5)
8 COMPARE_OP 0 (<)
10 POP_JUMP_IF_FALSE 16
4 12 LOAD_CONST 3 ('yes')
14 RETURN_VALUE
5 >> 16 LOAD_CONST 4 ('no')
18 RETURN_VALUE
조건부 코드 라인 3 if x < 5은 네 개의 명령어 LOAD_FAST, LOAD_CONST, COMPARE_OP와 POP_JUMP_IF_FALSE로 컴파일됩니다.
x < 5는 로드 x, 로드 5 및 두 값을 비교하는 코드를 생성합니다.
POP_JUMP_IF_FALSE 명령어는 인터프리터 스택에서 최상위 값을 확인하고 값이 참이면 아무 일도 일어나지 않습니다. 값이 False이면 인터프리터는 다른 명령어로 이동합니다.
POP_JUMP 명령의 인수를 점프 대상이라고 합니다. 여기서 점프 대상은 16입니다.
건너뛸 명령어 LOAD_CONST의 인덱스 16는 10 행에 있습니다. ( dis는 점프 대상에 >> 표시합니다.)
결과 x < 5가 False이면 인터프리터는 6행 (return "no")으로 곧 바로 건너 뛰고 4 행 (return "yes")을 건너 뜁니다.
인터프리터는 점프 명령어를 사용하여 명령어 세트의 일부를 건너뛸 수 있습니다.
파이썬 루프도 점프에 의존합니다. 아래의 바이트 코드에서 라인 while x < 5, if x < 10 두 경우가 그렇습니다.
비교 계산 POP_JUMP_IF_FALSE된 다음 다음에 실행될 명령어를 제어합니다.
바이트코드 22행에서 JUMP_ABSOLUTE을 통해 인터프리터를 루프 맨 위에있는 6행으로 다시 보냅니다.
x < 5가 거짓이되면 POP_JUMP_IF_FALSE 인터프리터가 루프 끝을 지나 24행으로 이동합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
>>> def loop():
... x = 1
... while x < 5:
... x = x + 1
... return x
...
>>> dis.dis(loop)
2 0 LOAD_CONST 1 (1)
2 STORE_FAST 0 (x)
3 4 SETUP_LOOP 20 (to 26)
>> 6 LOAD_FAST 0 (x)
8 LOAD_CONST 2 (5)
10 COMPARE_OP 0 (<)
12 POP_JUMP_IF_FALSE 24
4 14 LOAD_FAST 0 (x)
16 LOAD_CONST 1 (1)
18 BINARY_ADD
20 STORE_FAST 0 (x)
22 JUMP_ABSOLUTE 6
>> 24 POP_BLOCK
5 >> 26 LOAD_FAST 0 (x)
28 RETURN_VALUE
프레임
지금까지 Python 가상 머신이 스택 머신이라는 것을 배웠습니다. 명령어를 단계별로 이동하고 스택에서 값을 push하고 pop합니다.
위의 예에서 마지막 명령어는 코드 RETURN_VALUE의 return문에 의문이 들 것입니다.
이 질문에 답하려면 복잡한 계층인 프레임을 추가해야합니다. 프레임은 코드 청크에 대한 정보 및 컨텍스트의 모음입니다.
프레임은 Python 코드가 실행됨에 따라 즉시 생성 및 소멸됩니다. 각 함수 호출에 해당하는 하나의 프레임이 있습니다. 따라서 각 프레임에는 하나의 코드 객체가 연결되어 있지만 코드 객체에는 여러 프레임이 있을 수 있습니다. 자신을 10번 재귀적으로 호출하는 함수가 있다면 11 개의 프레임을 갖게됩니다.
각 재귀 수준에 대해 하나씩, 시작한 모듈에 대해 하나씩 입니다. 일반적으로 Python 프로그램에는 각 범위에 대한 프레임이 있습니다. 예를 들어, 각 모듈, 각 함수 호출 및 각 클래스 정의에는 프레임이 있습니다.
프레임은 지금까지 논의한 스택과 완전히 다른 스택인 호출 스택에 있습니다. (호출 스택은 이미 많이 보아온 스택일 것입니다. 예외의 트레이스 백에 출력된 것을 보셨을 것입니다. File 'program.py', line 10으로 시작하는 트레이스 백의 각 라인은 한 프레임에 해당합니다.)
우리가 살펴본 스택 (인터프리터가 바이트 코드를 실행하는 동안 조작하는 스택)을 데이터 스택 이라고 부릅니다. 블록 스택이라는 세 번째 스택도 있습니다.
블록은 특정 종류의 제어 흐름, 특히 루핑 및 예외 처리에 사용됩니다. 호출 스택의 각 프레임에는 각각의 데이터 스택과 블록 스택이 있습니다.
구체적으로 설명하자면, 파이썬 인터프리터가 현재 아래 3번째 라인을 실행하고 있다고 가정합니다.
인터프리터에서 foo 호출의 중간에 bar 호출이 있습니다. 이 다이어그램은 프레임, 블록 스택 및 데이터 스택의 호출 스택의 개략도를 보여줍니다.
foo()맨 아래에서를 실행 한 다음 foo의 본문에 도달한 다음 bar에 도달합니다.
1
2
3
4
5
6
7
8
9
10
11
>>> def bar(y):
... z = y + 3 # <--- (3) ... and the interpreter is here.
... return z
...
>>> def foo():
... a = 1
... b = 2
... return a + bar(b) # <--- (2) ... which is returning a call to bar ...
...
>>> foo() # <--- (1) We're in the middle of a call to foo ...
3
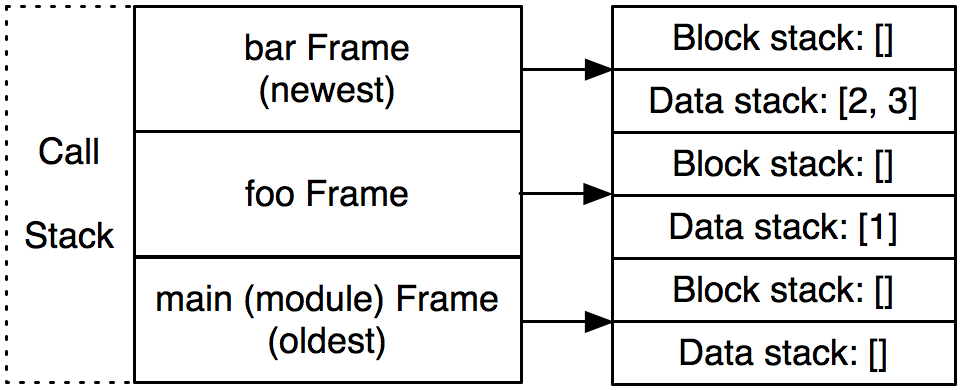
이 시점에서 인터프리터는 bar에 대한 함수 호출의 중간에 있습니다. 호출 스택에는 3개의 프레임이 있습니다. 하나는 모듈 레벨 용, 하나는 함수 foo용, 다른 하나는 bar 용입니다. bar가 반환되면 이와 관련된 프레임이 호출 스택에서 pop되고 사라집니다.
- 바이트 코드 명령어
RETURN_VALUE는 인터프리터에게 프레임간에 값을 전달하도록 지시합니다. - 호출 스택에 있는 최상위 프레임(현재 실행중인 프레임)의 데이터 스택에서 최상위 값을
pop합니다. - 전체 프레임을 호출 스택에서 꺼내어 버립니다. 마지막으로 값은 다음 프레임에서 데이터 스택으로 푸시됩니다.
Ned Batchelder와 제가 Byterun을 작업 할 때 오랫동안 구현에 심각한 오류가있었습니다. 각 프레임에 하나의 데이터 스택이 있는 대신 전체 가상 머신에 하나의 데이터 스택만 있었습니다. 우리는 Byterun과 실제 Python 인터프리터를 통해 실행한 작은 Python 코드 조각으로 구성된 수십 개의 테스트를 통해 두 인터프리터에서 동일한 일이 발생했는지 확인했습니다. 거의 모든 테스트가 통과되었습니다. 우리가 작동 할 수 없는 유일한 것은 generator였습니다. 마지막으로 CPython 코드를 더 주의 깊게 읽으면서 실수를 깨달았습니다. 데이터 스택을 각 프레임으로 이동하면 문제가 해결되었습니다.
이 버그를 되돌아 보면, 서로 다른 데이터 스택을 가진 각 프레임에 파이썬이 거의 의존하지 않는 것에 놀랐습니다. Python 인터프리터의 거의 모든 작업은 데이터 스택을 신중하게 정리하므로 프레임이 동일한 스택을 공유한다는 사실은 중요하지 않습니다. 위의 예에서 bar 실행이 완료 되면 데이터 스택을 비워 둡니다. foo 동일한 스택을 공유 하더라도 값은 낮아집니다. 그러나 제너레이터의 핵심 기능은 프레임을 일시 중지하고 다른 프레임으로 돌아간 다음 나중에 제너레이터 프레임으로 돌아가서 그대로 두었을 때와 똑같은 상태로 유지하는 기능입니다.
추가적인 내용은 Byterun의 구현임으로 본 포스팅에서는 다루지 않겠습니다.